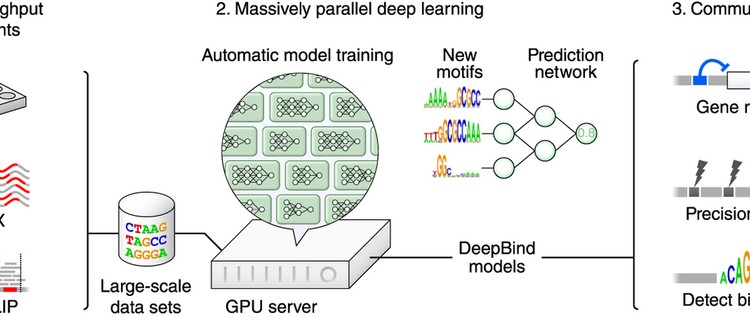
Knowing the sequence specificities of DNA- and RNA-binding proteins is essential for developing models of the regulatory processes in biological systems and for identifying causal disease variants. Here we show that sequence specificities can be ascertained from experimental data with ‘deep learning’ techniques, which offer a scalable, flexible and unified computational approach for pattern discovery. Using a diverse array of experimental data and evaluation metrics, we find that deep learning outperforms other state-of-the-art methods, even when training on in vitro data and testing on in vivo data. We call this approach DeepBind and have built a stand-alone software tool that is fully automatic and handles millions of sequences per experiment. Specificities determined by DeepBind are readily visualized as a weighted ensemble of position weight matrices or as a ‘mutation map’ that indicates how variations affect binding within a specific sequence.
Kategori: Makaleler
Makale: Massively Multitask Networks for Drug Discovery
Massively multitask neural architectures provide a learning framework for drug discovery that synthesizes information from many distinct biological sources. To train these architectures at scale, we gather large amounts of data from public sources to create a dataset of nearly 40 million measurements across more than 200 biological targets. We investigate several aspects of the multitask framework by performing a series of empirical studies and obtain some interesting results: (1) massively multitask networks obtain predictive accuracies significantly better than single-task methods, (2) the predictive power of multitask networks improves as additional tasks and data are added, (3) the total amount of data and the total number of tasks both contribute significantly to multitask improvement, and (4) multitask networks afford limited transferability to tasks not in the training set. Our results underscore the need for greater data sharing and further algorithmic innovation to accelerate the drug discovery process.
Makale: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224×224) input image. This requirement is “artificial” and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip the networks with another pooling strategy, “spatial pyramid pooling”, to eliminate the above requirement. The new network structure, called SPP-net, can generate a fixed-length representation regardless of image size/scale. Pyramid pooling is also robust to object deformations. With these advantages, SPP-net should in general improve all CNN-based image classification methods. On the ImageNet 2012 dataset, we demonstrate that SPP-net boosts the accuracy of a variety of CNN architectures despite their different designs. On the Pascal VOC 2007 and Caltech101 datasets, SPP-net achieves state-of-the-art classification results using a single full-image representation and no fine-tuning.
The power of SPP-net is also significant in object detection. Using SPP-net, we compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors. This method avoids repeatedly computing the convolutional features. In processing test images, our method is 24-102x faster than the R-CNN method, while achieving better or comparable accuracy on Pascal VOC 2007.
In ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014, our methods rank #2 in object detection and #3 in image classification among all 38 teams. This manuscript also introduces the improvement made for this competition.
Makale: Retrieving Similar Styles to Parse Clothing
Clothing recognition is a societally and commercially important yet extremely challenging problem due to large variations in clothing appearance, layering, style, and body shape and pose. In this paper, we tackle the clothing parsing problem using a retrieval-based approach. For a query image, we find similar styles from a large database of tagged fashion images and use these examples to recognize clothing items in the query. Our approach combines parsing from: pre-trained global clothing models, local clothing models learned on the fly from retrieved examples, and transferred parse-masks (Paper Doll item transfer) from retrieved examples. We evaluate our approach extensively and show significant improvements over previous state-of-the-art for both localization (clothing parsing given weak supervision in the form of tags) and detection (general clothing parsing). Our experimental results also indicate that the general pose estimation problem can benefit from clothing parsing.
Makale: TREETALK: Composition and Compression of Trees for Image Descriptions
We present a new tree based approach to composing expressive image descriptions that makes use of naturally occuring web images with captions. We investigate two related tasks: image caption generalization and generation, where the former is an optional subtask of the latter. The high-level idea of our approach is to harvest expressive phrases (as tree fragments) from existing image descriptions, then to compose a new description by selectively combining the extracted (and optionally pruned) tree fragments. Key algorithmic components are tree composition and compression, both integrating tree structure with sequence structure. Our proposed system attains significantly better performance than previous approaches for both image caption generalization and generation. In addition, our work is the first to show the empirical benefit of automatically generalized captions for composing natural image descriptions.