Makale Bağlantısı: Very Deep ConvNets for Large-Scale Image Recognition
Makale: Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively.

Doğal Dil İşleme için Derin Öğrenme
Machine learning is everywhere in today’s NLP, but by and large machine learning amounts to numerical optimization of weights for human designed representations and features. The goal of deep learning is to explore how computers can take advantage of data to develop features and representations appropriate for complex interpretation tasks. This tutorial aims to cover the basic motivation, ideas, models and learning algorithms in deep learning for natural language processing. Recently, these methods have been shown to perform very well on various NLP tasks such as language modeling, POS tagging, named entity recognition, sentiment analysis and paraphrase detection, among others. The most attractive quality of these techniques is that they can perform well without any external hand-designed resources or time-intensive feature engineering. Despite these advantages, many researchers in NLP are not familiar with these methods. Our focus is on insight and understanding, using graphical illustrations and simple, intuitive derivations. The goal of the tutorial is to make the inner workings of these techniques transparent, intuitive and their results interpretable, rather than black boxes labeled “magic here”. The first part of the tutorial presents the basics of neural networks, neural word vectors, several simple models based on local windows and the math and algorithms of training via backpropagation. In this section applications include language modeling and POS tagging. In the second section we present recursive neural networks which can learn structured tree outputs as well as vector representations for phrases and sentences. We cover both equations as well as applications. We show how training can be achieved by a modified version of the backpropagation algorithm introduced before. These modifications allow the algorithm to work on tree structures. Applications include sentiment analysis and paraphrase detection. We also draw connections to recent work in semantic compositionality in vector spaces. The principle goal, again, is to make these methods appear intuitive and interpretable rather than mathematically confusing. By this point in the tutorial, the audience members should have a clear understanding of how to build a deep learning system for word-, sentence- and document-level tasks. The last part of the tutorial gives a general overview of the different applications of deep learning in NLP, including bag of words models. We will provide a discussion of NLP-oriented issues in modeling, interpretation, representational power, and optimization.
Birinci Bölüm
İkinci Bölüm:
Sunum Materyali:
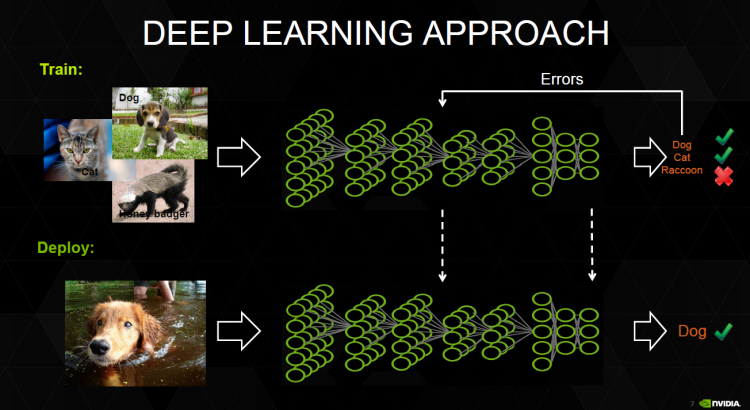
NVIDIA Derin Öğrenme Dersi #1 Soru ve Cevaplar
NVIDIA’nın düzenlemiş olduğu online derste (29.07.2015) katılımcıların yazılı sorularına verilen cevaplar aşağıda yer almaktadır. Dersle ilgili daha fazla bilgi için tıklayınız.
Chairperson: The recording and slides from the first class are located here https://developer.nvidia.com/deep-learning-courses
Jonathan Bentz: N Frick: I have a question: are any of the recent algorithm advances already “baked” into the DL Frameworks, or is it up to the user to choose the correct preprocessing methods and implement them outside the libraries?
A: Depends what you mean by “algorithm advances”. In general, the DL frameworks make every attempt to keep up with the current state of the art in deep learning algorithms and so they often implement these directly in the frameworks.
Brent Oster: Sunny Panchal: Once a network has been trained, how well does it adapt to a new set of data that is added with a new classification category?
Yes, this is referred to as fine tuning, and it works because many of the lower-level features are common between datasets. Only the weights for the fully-connected layers need to be adjusted.
Allison Gray: Earl Vickers Question: Can DIGITS handle arbitrary data types without a lot of programming, or is it mainly designed for pictures?
A: Right now you can use square or rectangular images with DIGITS. They can be either color or grayscale. We can also handle different image formats. We plan to expand this in the future.
Earl Vickers Question: Can DIGITS handle arbitrary data types without a lot of programming, or is it mainly designed for pictures?
A: Right now you can use square or rectangular images with DIGITS. They can be either color or grayscale. We can also handle different image formats. We plan to expand this in the future.
Earl Vickers Question: Can DIGITS handle arbitrary data types without a lot of programming, or is it mainly designed for pictures?
A: Right now you can use square or rectangular images with DIGITS. They can be either color or grayscale. We can also handle different image formats. We plan to expand this in the future.
Larry Brown: There are a few questions about invariance in DNNs and including metadata…those questions are more advanced and we will come back to them in a future session.
Brent Oster: Q: Ferhat Kurt: Is it possible to image recognition realtime in a stream (video)?