
Everything you wanted to know about ILSVRC: data collection, results, trends over the years, current computer vision accuracy, even a stab at computer vision vs. human vision accuracy — all here!

Makale: Deep Fragment Embeddings for Bidirectional Image-Sentence Mapping
We train a multi-modal embedding to associate fragments of images (objects) and sentences (noun and verb phrases) with a structured, max-margin objective. Our model enables efficient and interpretible retrieval of images from sentence descriptions (and vice versa).

Makale: Large-Scale Video Classification with Convolutional Neural Networks
We introduce Sports-1M: a dataset of 1.1 million YouTube videos with 487 classes of Sport. This dataset allowed us to train large Convolutional Neural Networks that learn spatio-temporal features from video rather than single, static images.
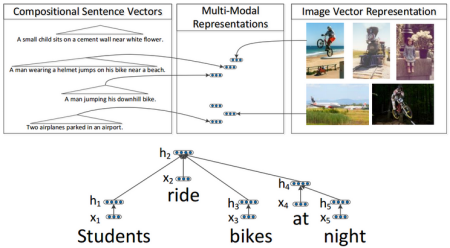
Makale: Grounded Compositional Semantics for Finding and Describing Images with Sentences
Our model learns to associate images and sentences in a common We use a Recursive Neural Network to compute representation for sentences and a Convolutional Neural Network for images. We then learn a model that associates images and sentences through a structured, max-margin objective.
Makale: Emergence of Object-Selective Features in Unsupervised Feature Learning
We introduce an unsupervised feature learning algorithm that is trained explicitly with k-means for simple cells and a form of agglomerative clustering for complex cells. When trained on a large dataset of YouTube frames, the algorithm automatically discovers semantic concepts, such as faces.