Current methods for training convolutional neural networks depend on large amounts of labeled samples for supervised training. In this paper we present an approach for training a convolutional neural network using only unlabeled data. We train the network to discriminate between a set of surrogate classes. Each surrogate class is formed by applying a variety of transformations to a randomly sampled ‘seed’ image patch. We find that this simple feature learning algorithm is surprisingly successful when applied to visual object recognition. The feature representation learned by our algorithm achieves classification results matching or outperforming the current state-of-the-art for unsupervised learning on several popular datasets (STL-10, CIFAR-10, Caltech-101).
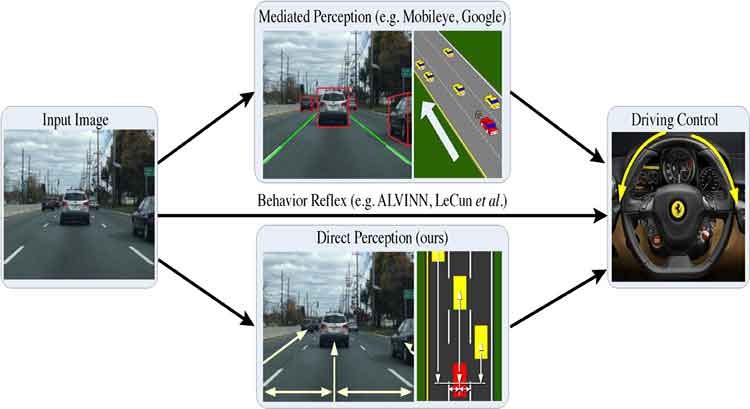
DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
Otonom araçların görüntü tabanlı olarak ilerlemesi tekniği üzerine Princeton Universitesi Vision Grubu’nun Google, Intel ve NVIDIA’nın desteğiyle yürüttüğü çalışmanın makalesi ve kodlamasının duyurusu yapıldı. Özellikle otonom araçların şerit ve araç takibini nasıl yapacağı üzerine mevcut yöntemlerle Convolution Neural Network yönteminin kıyaslamasını aşağıdaki videodadan izleyebilirsiniz.
Abstract:
Today, there are two major paradigms for vision-based autonomous driving systems: mediated perception approaches that parse an entire scene to make a driving decision, and behavior reflex approaches that directly map an input image to a driving action by a regressor. In this paper, we propose a third paradigm: a direct perception based approach to estimate the affordance for driving. We propose to map an input image to a small number of key perception indicators that directly relate to the affordance of a road/traffic state for driving. Our representation provides a set of compact yet complete descriptions of the scene to enable a simple controller to drive autonomously. Falling in between the two extremes of mediated perception and behavior reflex, we argue that our direct perception representation provides the right level of abstraction. To demonstrate this, we train a deep Convolutional Neural Network (CNN) using 12 hours of human driving in a video game and show that our model can work well to drive a car in a very diverse set of virtual environments. Finally, we also train another CNN for car distance estimation on the KITTI dataset, results show that the direct perception approach can generalize well to real driving images.
Derin Öğrenme Yaz Okulu 2015
Derin Öğrenme Yaz Okulu Montreal/Kanada’da Ağustos 2015 ayında icra edildi. 10 günlük faaliyette derin öğrenmenin kullanım alanlarına yönelik konusunda uzman kişilerin katıldığı sunumlar ve otonom sistem demoları yapıldı. Aşağıda günlük programlar halinde sunulan sunumları indirip inceleyebilirsiniz.
| 1’inci Gün – 03 Ağustos 2015 |
|---|
| Pascal Vincent: Intro to ML |
| Yoshua Bengio: Theoretical motivations for Representation Learning & Deep Learning |
| Leon Bottou: Intro to multi-layer nets |
| 2’nci Gün – 04 Ağustos 2015 |
|---|
| Hugo Larochelle: Neural nets and backprop |
| Leon Bottou: Numerical optimization and SGD, Structured problems & reasoning |
| Hugo Larochelle: Directed Graphical Models and NADE |
| Intro to Theano |
| 3’üncü Gün – 05 Ağustos 2015 |
|---|
| Aaron Courville: Intro to undirected graphical models |
| Honglak Lee: Stacks of RBMs |
| Pascal Vincent: Denoising and contractive auto-encoders, manifold view |
| 4’üncü Gün – 06 Ağustos 2015 |
|---|
| Roland Memisevic: Visual features |
| Honglak Lee: Convolutional networks |
| Graham Taylor: Learning similarit |
| 5’inci Gün – 07 Ağustos 2015 |
|---|
| Chris Manning: NLP 101 |
| Graham Taylor: Modeling human motion, pose estimation and tracking |
| Chris Manning: NLP / Deep Learning |
| 6’ncı Gün – 08 Ağustos 2015 |
|---|
| Ruslan Salakhutdinov: Deep Boltzmann Machines |
| Adam Coates: Speech recognition with deep learning |
| Ruslan Salakhutdinov: Multi-modal models |
| 7’nci Gün – 09 Ağustos 2015 |
|---|
| Ian Goodfellow: Structure of optimization problems |
| Adam Coates: Systems issues and distributed training |
| Ian Goodfellow: Adversarial examples |
| 8’inci Gün – 10 Ağustos 2015 |
|---|
| Phil Blunsom: From language modeling to machine translation |
| Richard Socher: Recurrent neural networks |
| Phil Blunsom: Memory, Reading, and Comprehension |
| 9’uncu Gün – 11 Ağustos 2015 |
|---|
| Richard Socher: DMN for NLP |
| Mark Schmidt: Smooth, Finite, and Convex Optimization |
| Roland Memisevic: Visual Features II |
| 10’uncu Gün – 12 Ağustos 2015 |
|---|
| Mark Schmidt: Non-Smooth, Non-Finite, and Non-Convex Optimization |
| Aaron Courville: VAEs and deep generative models for vision |
| Yoshua Bengio: Generative models from auto-encoder |
Tüm sunumları indirmek için tıklayınız.
Kaynaklar:
Understanding Neural Networks Through Deep Visualization
Recent years have produced great advances in training large, deep neural networks (DNNs), including notable successes in training convolutional neural networks (convnets) to recognize natural images. However, our understanding of how these models work, especially what computations they perform at intermediate layers, has lagged behind. Progress in the field will be further accelerated by the development of better tools for visualizing and interpreting neural nets. We introduce two such tools here. The first is a tool that visualizes the activations produced on each layer of a trained convnet as it processes an image or video (e.g. a live webcam stream). We have found that looking at live activations that change in response to user input helps build valuable intuitions about how convnets work. The second tool enables visualizing features at each layer of a DNN via regularized optimization in image space. Because previous versions of this idea produced less recognizable images, here we introduce several new regularization methods that combine to produce qualitatively clearer, more interpretable visualizations. Both tools are open source and work on a pre-trained convnet with minimal setup.
Makale: Going Deeper With Convolutions
We propose a deep convolutional neural network architecture codenamed Inception that achieves the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC2014). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. By a carefully crafted design, we increased the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation of this architecture, GoogLeNet, a 22 layers deep network, was used to assess its quality in the context of object detection and classification.