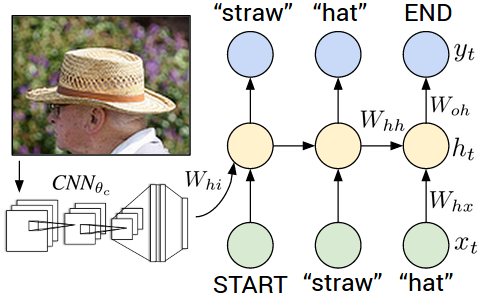
We present a model that generates free-form natural language descriptions of full images and their regions. For generating sentences about a given image region we describe a Multimodal Recurrent Neural Network architecture. For inferring the latent alignments between segments of sentences and regions of images we describe a model based on a novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding. This work was also featured in a New York Times article.